Python 기초
- 위키 표지
- Python이란?
- Python의 특징
- Python으로 무엇을 할 수 있나요?
- 편집기 설치
- Python 프로젝트 만들기
- 대화형 창 이용하기
- Hello World!
- 터틀 그래픽
- 변수와 계산
- 변수의 소개
- 변수와 상수
- 수식과 연산자
- 연산자의 우선 순위
- 함수 호출이란?
- input() 함수
- 자료형
- 문자열
- 리스트
- 파이썬에서의 변수 개념
- 선택
- 조건문
- 블록
- 논리 연산자
- 연속적인 if-else문
- 중첩 if-else문
- 문자열 <-> 숫자
- 반복
- 반복의 필요성
- for 문
- while 문
- 보초값(sentinel) 사용하기
- 중첩 루프
- 문자열 처리하기
- 함수
- 함수란?
- 함수의 정의
- 함수 작성의 예 #1 : square()
- 함수 작성의 예 #2 : max()
- 함수 작성의 예 #3 : power()
- 인수와 매개 변수
- 값을 반환하지 않는 함수
- 디폴트 인수
- 키워드 인수
- 참조값에 의한 인수 전달
- 지역 변수와 전역 변수
- 여러 개의 값 반환하기
- 무명 함수(람다식)
- 모듈이란?
- 함수를 사용한 프로그램 설계
- 리스트
- 리스트란?
- 시퀀스 자료형
- 인덱싱과 슬라이싱
- 리스트의 기초 연산들
- 리스트 복사하기
- 리스트와 함수
- 리스트 함축
- 일반적인 리스트 연산들
- 2차원 리스트란?
- 2차원 리스트 연산
- 튜플, 세트, 딕셔너리, 문자열
- 자료 구조란?
- 튜플
- 세트(Set)
- 딕셔너리
- 문자열
- 클래스와 객체
- 객체 지향 프로그래밍이란?
- 클래스 작성하기
- 생성자
- 메소드 정의
- 정보 은닉
- 접근자와 설정자
- 객체를 함수로 전달할 때
- 클래스 변수
- 특수 메소드
- 파이썬에서의 변수의 종류
- 내장 함수와 모듈
- 내장 함수
- 파이썬에서 정렬하기
- 이터레이터와 제너레이터
- 연산자 오버로딩
- 모듈이란?
- 유용한 모듈
- 상속과 다형성
- 상속의 개념
- 상속 구현하기
- 왜 상속을 사용하는가?
- 부모 클래스의 생성자 호출
- 메소드 오버라이딩
- 다형성
- object 클래스
- 클래스 관계
- 파일과 예외처리
- 파일
- 파일의 개념
- 파일의 종류
- 텍스트 파일 읽고 쓰기
- 텍스트 입출력 기법
- 이진 파일과 임의 접근 파일
- 예외 처리
- 예외 발생하기
이진 파일
여기서 다시 한 번 텍스트 파일과 이진 파일의 차이점을 살펴봅시다. 텍스트 파일에서는 모든 정보가 문자열로 변환되어서 파일에 기록되었습니다.
즉 정수값도 print()를 통하여 문자열로 변환된 후에 파일에 쓰였습니다. 즉 123456과 같은 정수값을 화면에 출력하려면 6개의 문자 '1', '2', '3', '4', '5', '6' 으로 변환하여 출력하였습니다.
이 변환은 print() 함수가 담당하였습니다.
반면에 이진 파일(binary file)은 데이터가 직접 저장되어 있는 파일입니다. 즉 정수 123456은 문자열로 변환되지 않고 이진수 형태로 그대로 파일에 기록되는 것입니다.
이진 파일의 장점은 효율성입니다. 즉 텍스트 파일에서 숫자 데이터를 읽으려면 먼저 문자를 읽어서 이것을 int()와 같은 함수를 사용하여 숫자로 변환하여야 하기 때문입니다.
이 과정은 시간이 많이 걸리며 비효율적입니다. 이진 파일을 사용하면 이러한 변환 과정이 필요 없이 바로 숫자 데이터를 읽을 수 있으며 텍스트 파일에 비하여 저장 공간도 더 적게 차지합니다.
이진 파일의 단점은 인간이 파일의 내용을 확인하기가 힘들다는 점입니다. 문자 데이터가 아니므로 모니터나 프린터로 출력하는 것이 불가능합니다.
또한 텍스트 파일은 컴퓨터의 기종이 달라도 파일을 이동할 수 있습니다. 왜나하면 아스키 코드로 되어 있기 때문에 다른 컴퓨터에서도 읽을 수 있기 때문입니다.
그러나 이진 파일의 경우, 정수나 실수 데이터를 표현하는 방식이 컴퓨터 시스템마다 다를 수 있기 때문에 이식성이 떨어집니다.
따라서 이식성이 중요하다면 약간 비효율적이더라도 텍스트 형식의 파일을 사용하는 것이 좋습니다. 하지만 데이터가 상당히 크고 실행 속도가 중요하다면 이진 파일로 하는 것이 좋을 것입니다.
이진 파일에서 데이터를 읽으려면 아래와 같이 파일을 열어야 합니다.
infile = open(filename, "rb")
입력 파일에서 8 바이트를 읽으려면 아래와 같은 문장을 사용합니다.
bytesArray = infile.read(8)
bytesArray는 바이트형의 시퀀스로서 0부터 255까지의 값들의 모임입니다. 첫 번째 바이트를 꺼내려면 아래와 같은 문장을 사용하면 됩니다.
bytes1 = bytesArray[0]
이진 파일에 바이트들을 저장하려면 아래와 같이 합니다.
outfile = open(filename, "wb")
bytesArray = bytes([255, 128, 0, 1])
outfile.write(bytesArray)
순차 접근과 임의 접근
지금까지의 파일 입출력 방법은 모두 데이터를 파이르이 처음부터 순차적으로 읽거나 기록하는 것이었습니다. 이것을 순차 접근(sequential access) 방법이라고 합니다.
이러한 방법은 한번 읽은 데이터를 다시 읽으려면 현재의 파일을 닫고 파일을 다시 열어야 합니다. 또한 앞부분을 읽지 않고 중간이나 마지막으로 건너뛸 수도 없습니다.
또다른 파일 입출력 방법으로 임의 접근(random access) 방법이 있습니다. 임의 접근 방법은 파일의 어느 위치에서든지 읽기와 쓰기가 가능합니다.
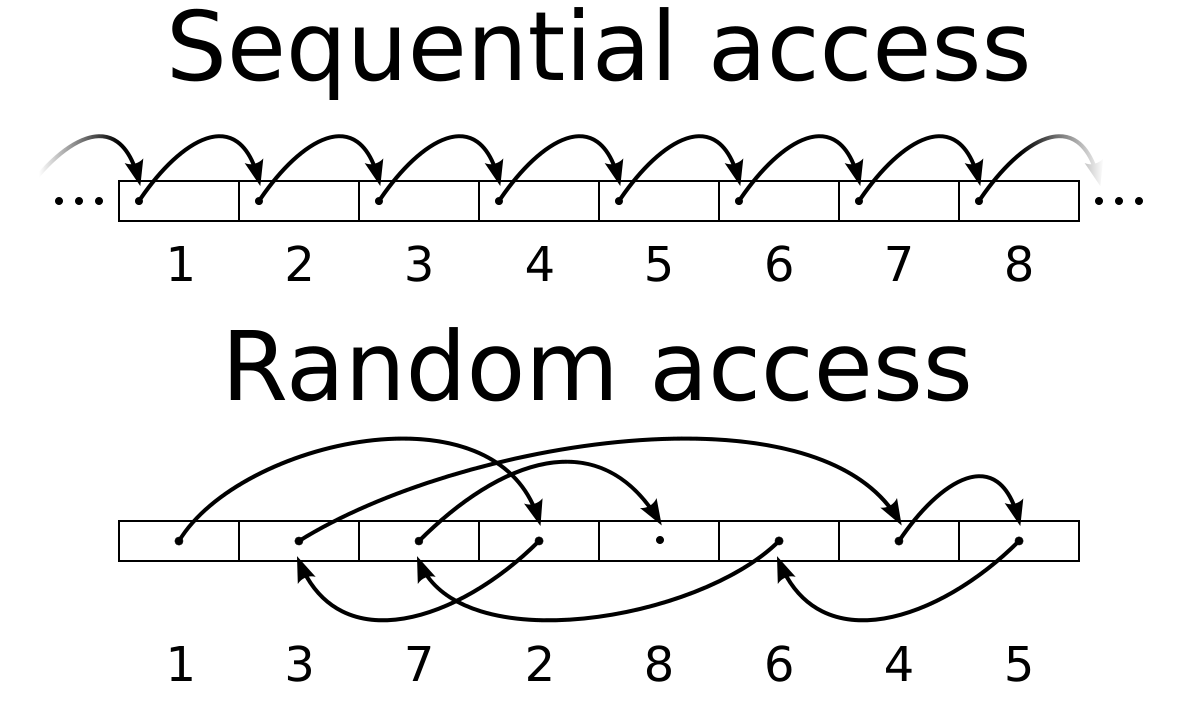
임의 접근의 원리
모든 파일에는 위치 표시자(file pointer)라는 것이 존재합니다. 위치 표시자는 읽기와 쓰기 동작이 현재 어떤 위치에서 이루어지는 지를 나타냅니다.
새 파일이 만들어 지게 되면 위치 표시자는 값이 0이고 이것은 파일의 시작 부분을 가리킵니다.
기존의 파일의 경우, 추가 모드에서 열렸을 경우에는 파일의 끝이 되고, 다른 모드인 경우에는 파일의 시작 부분을 가리킵니다.

파일에서 읽기나 쓰기가 수행되면 위치 표시자가 갱신됩니다. 예를 들어 읽기 모드로 파일을 열고, 100바이트를 읽었다면 위치 표시자의 값이 100이 됩니다.
다음에 다시 200바이트를 읽었다면 위치 표시자는 300이 됩니다. 우리가 입출력 함수를 사용하면 그 함수의 내부에서 위치 표시자의 값이 변경됩니다.
사실 프로그래머는 위치 표시자에 대하여 크게 신경 쓸 필요는 없습니다.
보통 순차적으로 데이터를 읽게 되면 위치 표시자는 파일의 시작 위치에서 순차적으로 증가하여 파일의 끝으로 이동합니다.
그러나 만약 파일의 데이터를 전체를 다 읽지 않고 부분적으로 골라서 읽고 싶은 경우에는 위치 표시자를 이동시켜서 임의 파일 액세스를 할 수 있습니다.
임의(random)이라는 말은 임의의 위치에서 데이터를 읽을 수 있다는 의미입니다.
예를 들어서 데이터를 파일의 시작 부분으로부터 1000바이트 위치에서 읽었다가 다시 시작 위치로부터 500바이트 떨어진 위치에서 읽어야 하는 경우도 있습니다.
즉 데이터를 임의의 위치에서 읽는 기능이 필요한 경우도 있는 것입니다. 이때는 위치 표시자를 조작하여야만이 파일을 원하는 임의의 위치에서 읽을 수 있습니다.
위치 표시자를 조작하는 함수는 seek() 입니다.
infile.seek(position)
현재의 위치는 tell() 함수로 알 수 있습니다.
텍스트 파일에서 몇 개의 문자를 읽은 후에 seek() 함수를 이용하여 다시 파일의 처음으로 돌아가 봅시다.
읽을 파일은 test.txt 라는 이름을 가진 파일이며 "테스트 데이터를 파일에 씁니다!!!" 라는 내용이 적혀 있습니다.
infile = open("test.txt", "r+")
str = infile.read(10)
print("읽은 문자열 : ", str)
position = infile.tell()
print("현재 위치 : ", position)
position = infile.seek(0, 0) # 파일의 처음으로 갑니다.
str = infile.read(10)
print("다시 읽은 문자열 : ", str)
infile.close()
<실행 결과>
읽은 문자열 : 테스트 데이터를 파
현재 위치 : 18
다시 읽은 문자열 : 테스트 데이터를 파
객체 입출력
우리는 앞에서 문자열을 파일에 쓰는 방법을 학습하였습니다. 객체도 파일에 쓸 수 있을까요? 예를 들어서 리스트나 사전과 같은 객체를 파일에 쓰고 읽을 수 있다면 상당히 편리할 것입니다.
파이썬에서는 다양한 방법이 제공됩니다. 가장 많이 사용되는 모듈은 pickle 모듈입니다. pickle 모듈의 dump()와 load() 메소드를 사용하면 객체를 쓰고 읽을 수 있습니다.
딕셔너리에 저장된 데이터들을 pickle 모듈을 이용하여 파일에 기록하는 예제를 살펴봅시다.
import pickle
myMovie = { "Superman vs Batman " : 9.8, "Ironman" : "9.6" }
# 딕셔너리를 피클 파일에 저장합니다.
pickle.dump(myMovie, open("save.p", "wb"))
# 피클 파일에 딕셔너리를 로딩합니다.
myMovie = pickle.load(open("save.p", "rb"))
print(myMovie)
<실행 결과>
{'Superman vs Batman ': 9.8, 'Ironman': '9.6'}
피클 객체는 파이썬 객체 구조를 직렬화하고 역직렬화하는 이진 프로토콜을 구현합니다.
피클 객체의 dump()를 호출하면 파이썬 객체 계층 구조가 바이트 스트림으로 변환되고, load()를 호출하면 바이트 스트림이 객체 계층 구조로 변환됩니다.
도전 과제
이미지 파일은 이진 파일입니다. 즉 파일에 데이터가 이진수 형식으로 저장되어 있습니다. 하나의 이미지 파일을 다른 이미지 파일로 복사하는 프로그램을 작성하여 봅시다.
<실행 결과>
원본 파일 이름을 입력하세요 : seulgi_dumbdumb.jpg
복사 파일 이름을 입력하세요 : copy.jpg
seulgi_dumbdumb.jpg를 copy.jpg로 복사하였습니다.